whoami¶
- じょんすみす
- クラスメソッド株式会社
- データインテグレーション(DI)部 ML推進チームリーダー
やってること¶
- Hadoop/Sparkおじさん
- 機械学習の人
- Alteryxの人
本日の内容¶
- Jupyter Notebookの基本的な機能をサラッと紹介
- たぶん今日の内容だけで最低限使えるけど興味を持って詳しく知りたくなったら調べてね☆彡
インタラクティブな環境とは¶
- 通常のプログラム
- 処理全体を記述したスクリプトを一括で実行する
- Pythonの場合、.pyファイルを指定してpythonコマンドを実行
- 一連の流れを一通り記述したのち全体を実行するので細かい単位での処理内容の確認が難しい
- ファイルの内容に変更がなければ常に同じ結果を得られる
- インタラクティブな環境
- いわゆるREPL
- Pythonの場合、.pyを指定せずにpythonコマンドを実行
- 1行記述して実行を繰り返していく
- 細かい単位で処理結果を確認できる
- 記述した内容を保存しておけない

Jupyter Notebookとインタラクティブな環境¶
Jupyter Notebookを使えばインタラクティブにスクリプトを実行しながら処理内容も保存しておける
In [1]:
print('Hello')
処理は複数行・複数命令を記述可能¶
In [2]:
items = ['ピーター', 'フロプシー', 'モプシー', 'カトンテール', 'ベンジャミン']
for index, item in enumerate(items) :
print('{}: {}'.format(index, item))
# セル内の一番最後の処理の戻り値は変数で受け取らなければそのまま出力される
result = 'Done'
result
Out[2]:
関数などの定義のみのセルも作成可能¶
In [3]:
def rabbit_function() :
pass
class rabbit_class:
def rabiit_method() :
pass
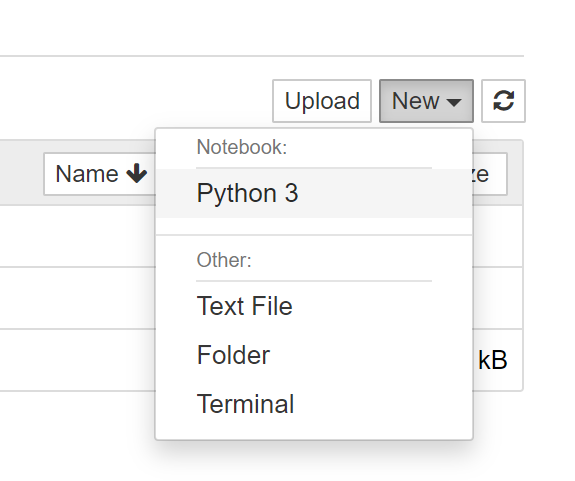
- ブラウザの新規タブで立ち上がり以下のような画面が表示される(localhost:8888を直接入力してもok)

- 右上の[new] > [Python3]を選択することによって新規Notebookを作成
プログラムの処理単位とセル¶
- セルと言われる単位でプログラムを実行する
- セル内に処理を記述して実行(Shift-EnterまたはCtrl-Enter)
- セルの追加・削除は自由に行える
- コマンドモードと編集モード
- Escキーを押してコマンドモードへ移行
- コマンドモードではカーソルキー上下でセル間の移動
aで現在セルの上、bで下に新しいセルを追加ddでセルの削除Enterで現在のセルに対して変数モードに移行
- Escキーを押してコマンドモードへ移行
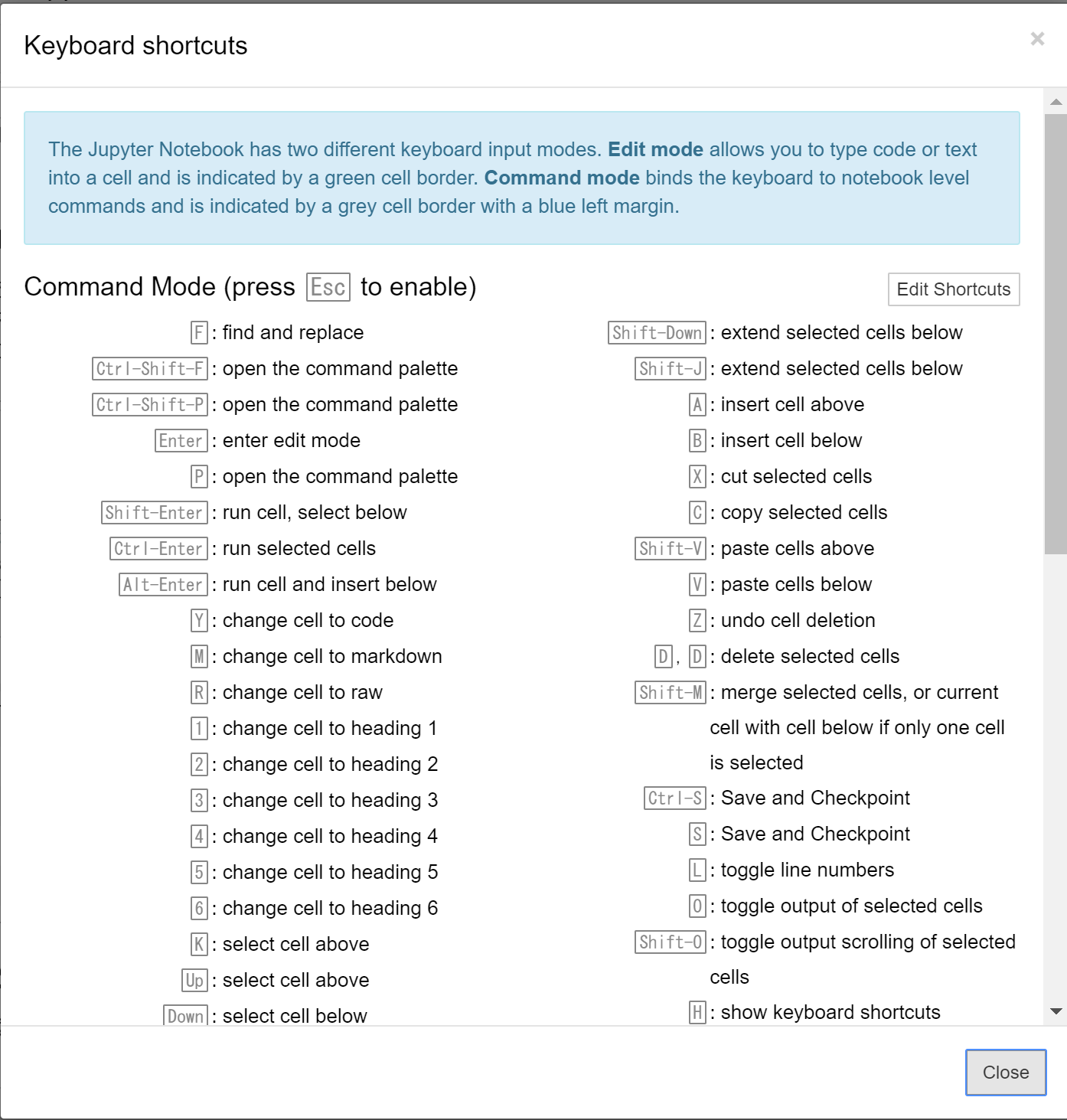
- その他のショートカット
hで一覧表示
Notebookの保存¶
- Notebookはファイルとして保存しておける
- .ipynbファイル
- 中身はJSON
- 実行結果なども含めて保存されるので次回開いたときにその情報が残ってる
Jupyter Notebookのマジックコマンド¶
Jupyter Notebookはマジックコマンドをというものを利用することで様々なことが行える
マジックコメントを利用するには先頭に%を付けて実行する
処理時間の計測¶
処置時間を計測する%time
In [5]:
%time sum(range(100000))
Out[5]:
%timeitを使うことで複数回計測して統計情報も出す
In [6]:
%timeit sum(range(10000))
複数行にわたる処理の時間を計測する場合は%%を使う
In [7]:
%%time
import random
items = [random.randint(1, 10) for _ in range(10000)]
sum(items)
過去の実行履歴を確認する¶
In [8]:
%history
変数の確認¶
In [9]:
%who
In [10]:
%whos
コマンドの実行¶
In [11]:
%%bash
ls
In [12]:
!pip list
利用可能なマジックコマンド一覧¶
In [13]:
%lsmagic
Out[13]:
CodeセルとMarkdownセル¶
- NotebookのセルはPythonコードのみでなく、テキストやMarkdownの記述も可能
- これによってコードとして再現可能なドキュメント化や実行可能な手順書としての利用することも可能
セルをMarkdownに変更¶
- コマンドモードで
mを押すことで現在のセルをMarkdownに変更
ここにMarkdownでドキュメントを記載します。
セルをCodeに変更¶
- デフォルト状態ではCodeになっている
- MarkdownのセルをCodeに戻したい場合は
yを押す
In [14]:
# ここにコードを記述して実行可能
print('Hello')
データ分析環境としてのJupyter Notebook¶
- Juypter Notebookはデータ分析に利用されるPandasやMatplotlibとの親和性が高い
PandasのDataFrame表示¶
- データ分析でよく使われるライブラリ
- DataFrame(RDBのテーブルような形式)でデータをまとめて持っておける
- RDBのSQLに対応するような様々な操作を機能として提供している
In [15]:
import pandas as pd
from sklearn.datasets import load_iris
iris = load_iris()
In [16]:
# データは1件のデータが4つの観測値を持つ
# 1件のデータが長さ4の配列でさらにそれがデータ件数分の2次元配列になっている
iris['data'][:5]
Out[16]:
In [17]:
# 各観測値が何を計測した値なのかはfeature_names
iris['feature_names']
Out[17]:
In [18]:
# このデータをDataFrameにする
df = pd.DataFrame(iris['data'], columns=map(lambda x : x[:-5].replace(' ', '_'), iris['feature_names']))
print(df.head())
In [19]:
# テーブルに整形された表示
df.head()
Out[19]:
Matplotlibのグラフをインライン表示¶
- グラフを生成するライブラリ
In [20]:
%matplotlib inline
In [21]:
df.plot.scatter(x='petal_length', y='petal_width')
Out[21]:

Notebookの共有¶
- NotebookはGithubに上げるとRead Onlyでそのまま表示可能
- 実行番号や出力もそのまま含まれるの以下をやっておくといい
- 出力を含めない場合は Kernel > Restart & Clear Output
- 出力も含めて共有する場合は Kernel > Restart & Run All
- 共有前は一度 Kernel > Restart & Run All をして上から順に実行できるか確認しておくとよい
- Jupyter Notebookで作業中は前後のセルを行ったり来たりも多い
- 変数の定義場所などの関係で上からやると動かず同じ結果を再現できない場合がある
実際のNotebook例¶
その他機能について¶
- 本日紹介していないけど便利な機能
- 動的なグラフを描画
- Extensionで拡張
- Python以外の言語を動かすためのKernel導入
- この資料もJupyter Notebookで作成
まとめと注意点¶
- Jupyter Notebookの紹介
- 保存・再利用可能なインタラクティブなPython実行環境
- マジックコマンド・Markdownでドキュメント化といった便利機能
- データ分析環境としての活用
- Githubを使っての共有
- 注意点
- Notebookは試行錯誤しながらプログラムを記述するのでコードが汚くなりがち
- 例外などもその場で見て確認→修正となるのでハンドリングされてないことが多い
- .pyファイルとしてそのまま出力することも可能だが本番利用の歳は要注意